01. Overview
Background · Problem · Solution
Background
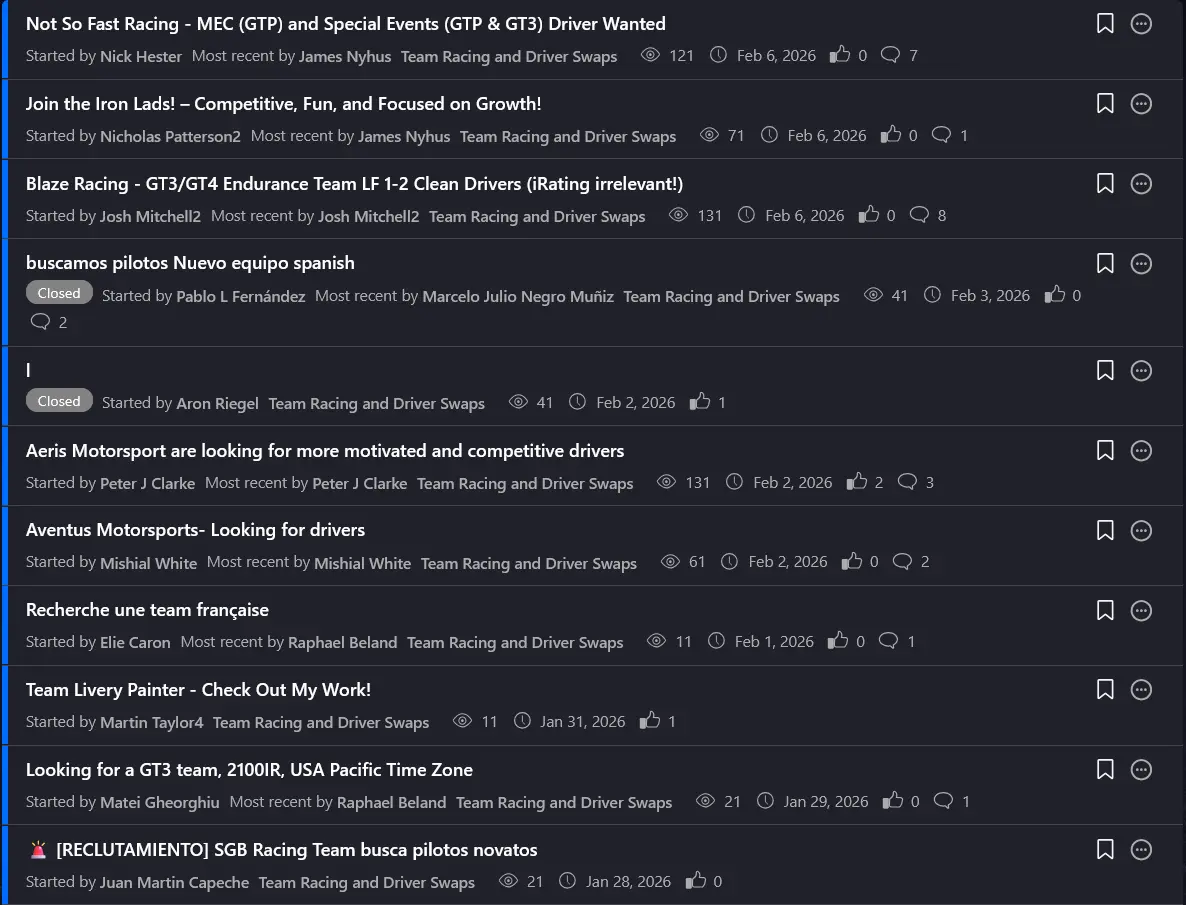
Sim racing is primarily built around team events. However, there are no effective methods of putting together a team. For the bigger endurance events, you realistically need around four drivers. Currently, that takes weeks, and sometimes even months, to find the right fit for your team.
Problem
To find a driver for your team, you'd have to post on a forum and wait. Any reply meant scheduling a voice call just to collect basic info. A process that could live on a single web page was strung across weeks of DMs.Sim racing teams aren't organisations but are grassroot-esque teams born from a driver who took initiative.
Solution
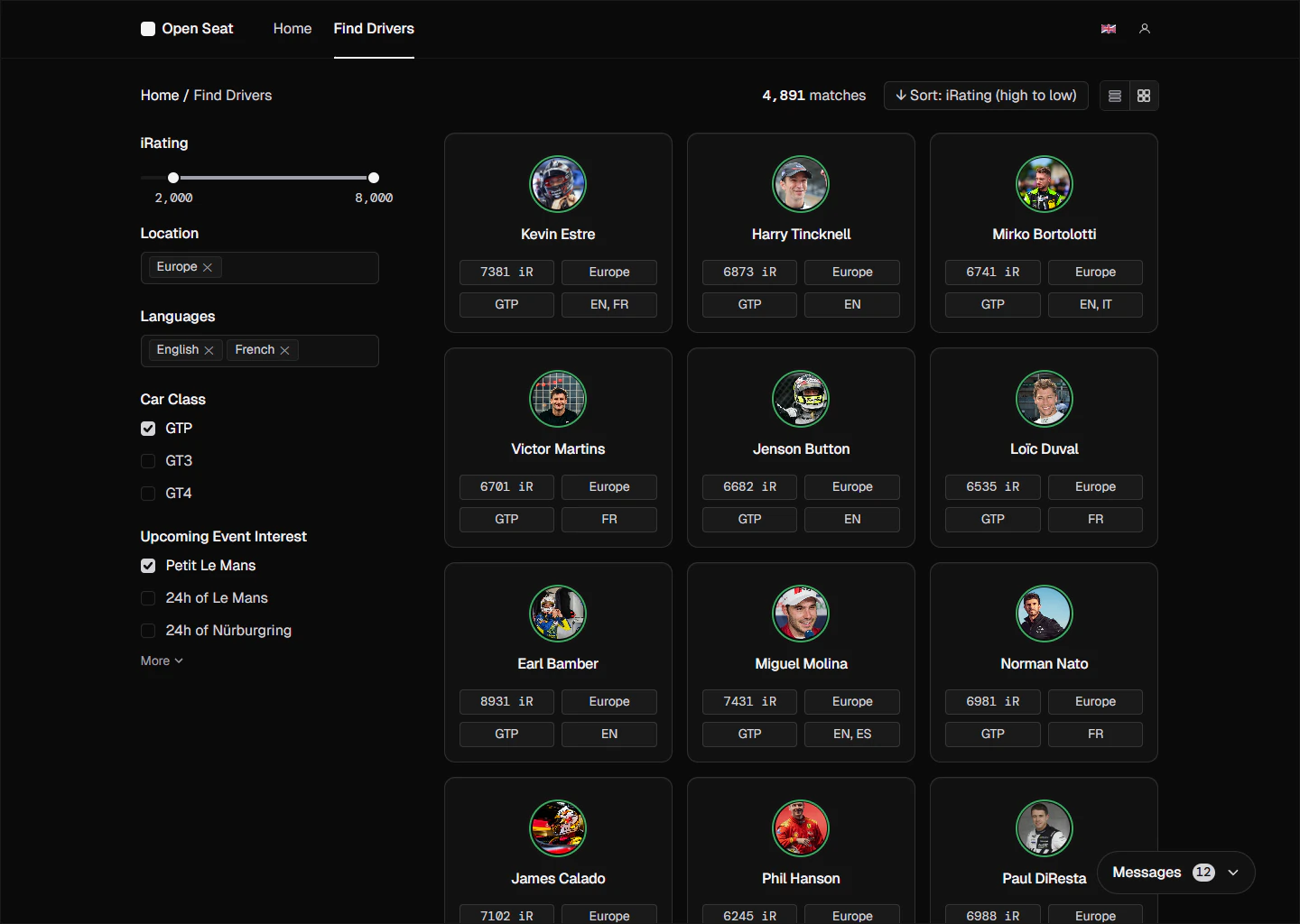
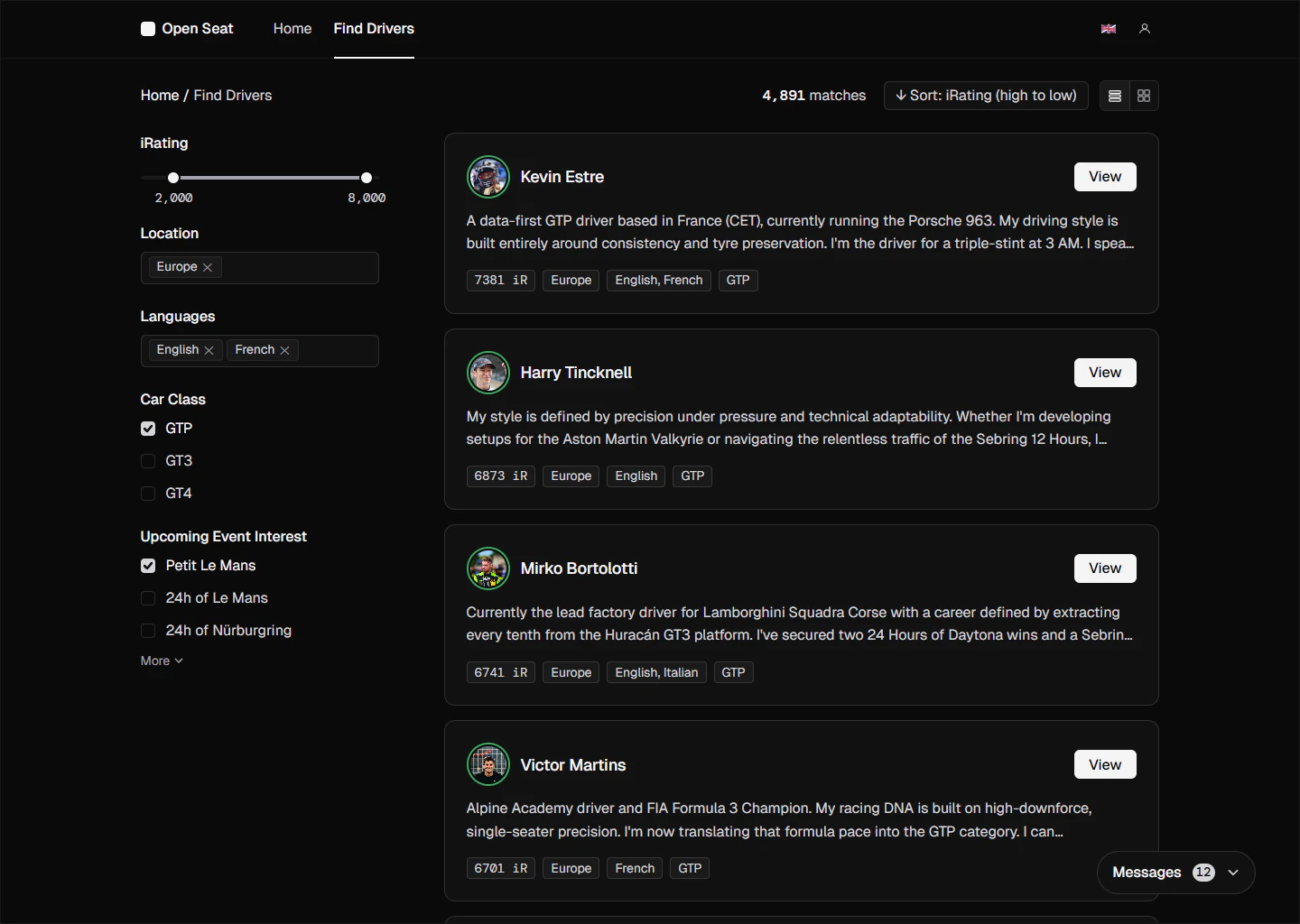
Open Seat is a dedicated recruitment platform for sim racing teams. It replaces the fragmented, informal process of forums posts and DMs with a structured directory where drivers connect their verified iRacing accounts. Managers search the pool, review actual stats alongside community endorsements, and reach out directly — turning weeks of vetting into a few clicks.